Speaker(s)
Experience level
IntermediateDuration
50 minAccording to IDC, 90% of all the digital information is unstructured locked in multiple repositories and digital businesses have either underinvested in technology or invested in substandard technology in order to access them. Traditional search method leads to failures majorly due to the absence of optimisation practices and lack of unified framework. In a data-driven world, unlocking the hidden insights, that are shut off from view within both structured and unstructured data present in multiple repositories, is more critical than ever.
Today, the sheer quantity and the pace of digital information that knowledge workers have to deal with every day are dramatically increasing. To tame the chaos of multiple repositories is a challenge. There has to be a deployment of a search method over distributed and heterogeneous data sets in order to receive a unified results list. This brings us to Federated Search.
OpenSense Labs initiated one such enterprise search tinkering robust Apache Solr and versatile Drupal 8 for eleven different websites with a great variation in CMS leveraging portability using Node JS.
In this session, we will equip you with the know-how of:
- Enhancing website search experience retaining a blend of useful and accurate results
- Expanding inter-site searchability decreasing the bounce rate and latency
- Increasing data discovery and interoperability of information by cross-functional support to a plethora of platforms
Architecture which will be walked through in the Session.
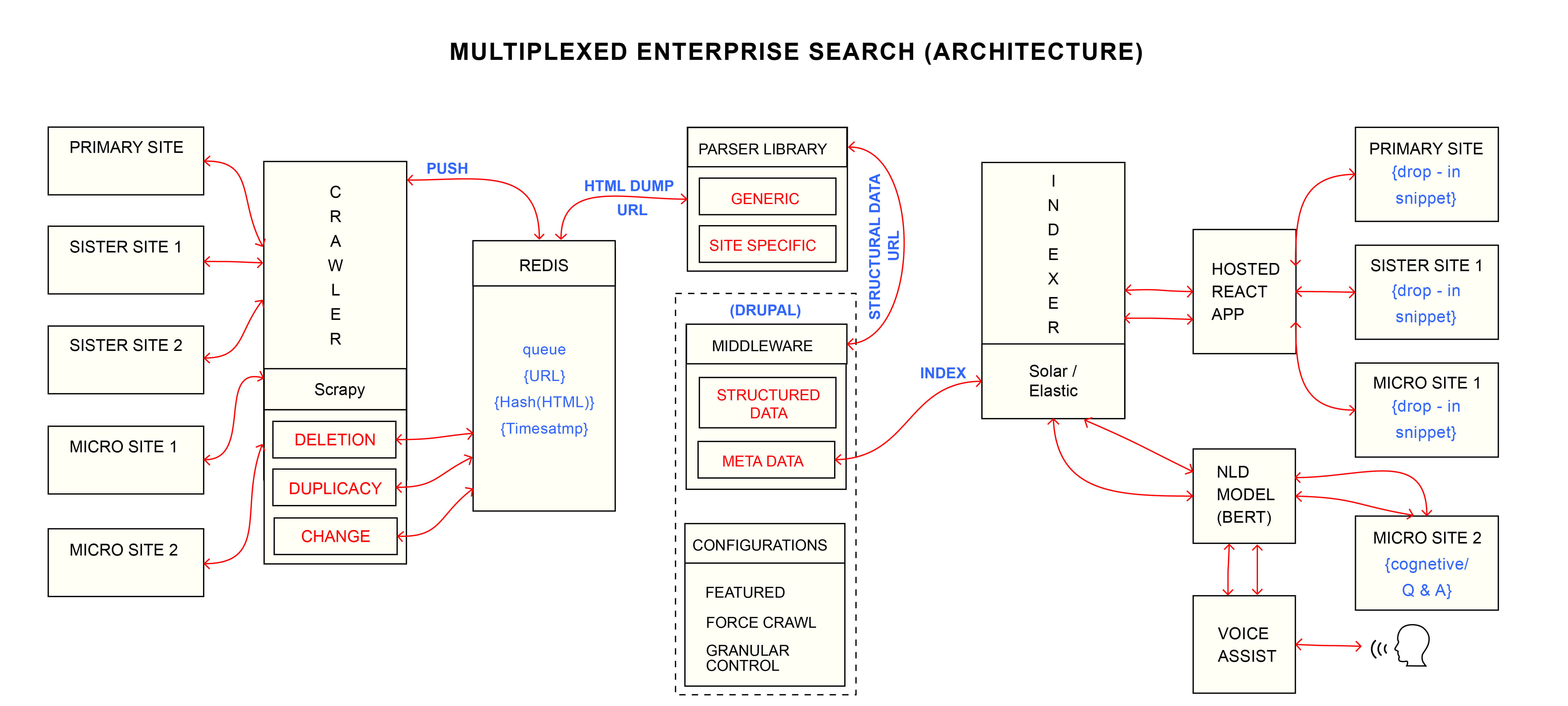
The major takeaways would be:
- Challenges amidst architecting a microservice
- Scraping content using an open-source tool like Scrappy
- Choosing the right set of stack and technologies.
- Fiddling the Solr configuration and boosting queries
- Create a pluggable and platform agnostic search UI with react.
- What to keep in mind while building a cognitive voice search.